
Implementing and Rolling Out Crypto-Shredding for Data Encryption and Deletion
Introduction
Here at Rent the Runway, we take great care to make sure that our sensitive data is not only securely stored, but also properly deleted when required.
Crypto-shredding is a way of destroying data through the destruction of the encryption keys protecting the data. Once an entry’s encryption key is deleted, the encrypted data will be un-decryptable— like a safe without the combination.
We chose crypto-shredding as our solution because it handles data at-rest as well as data in-motion, and it considerably reduces data removal costs, but it also brings significant technical complexity. In this blog post, I will try to answer the question:
“What did it mean to implement and roll out crypto-shredding at Rent the Runway, and what might it mean for you, if you are thinking about implementing it for your organization as well?”
Implementation
In order to crypto-shred data, the data first needed to be encrypted. We chose to encrypt the data in two layers of encryption. Single-layer encryption meant assigning each entry with a unique encryption key, meaning a hacker just needed a snapshot of the DB to decrypt all the data. A second layer further secured our keys by encrypting each entry’s unique key with a master encryption key, stored in a different location (or you could use a secure third party such as SQL server’s EKM). This two-layer encryption meant that someone would need access to both the database and the master key in order to decrypt the data.
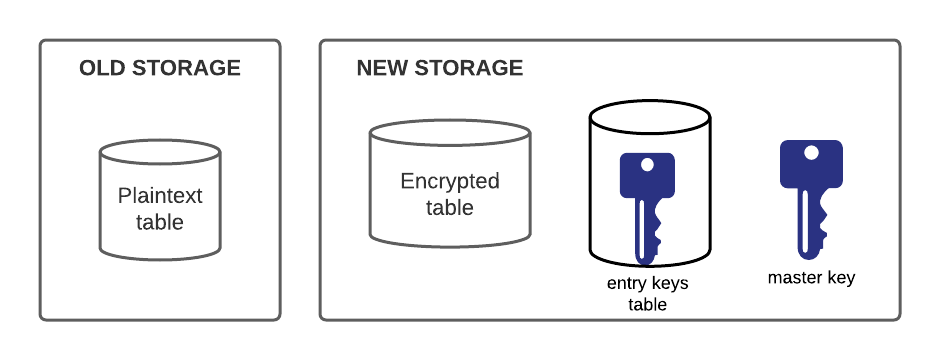
Old Flow
Receive request to get/update/create entry
Get/update/create entry from/in database
New Flow


Rollout
We knew we wanted to minimize the risk during rollout, so we broke the process into 3 phases.
Phase 1
Planning: Start writing to the new encrypted table
In this phase, when a new entry is created or updated, we would write the data into the new encrypted table. However, to reduce risk, we would continue to write to the old plaintext table. This way, in case there’s any issue encrypting or writing to the new table, we would still have the old plaintext table to rely on.
This would also be the phase during which we would run our backfill job, where we would generate an individual key for each entry, encrypt the data, and save them to the new encrypted table.
Reality: Start writing to the new encrypted table...twice
Since we decided to prioritize consistency between the plaintext and the encrypted tables, we didn’t allow changes to the plaintext table to go through if there was an issue writing to the new encrypted table. This enforcement of consistency meant that the write action wasn’t able to go through (as opposed to allowing the write to go through to the plaintext table, but then the data might be inconsistent between the plaintext and the encrypted tables). Therefore, when we detected bugs during this phase, we had to turn the write off, fix the bug, then turn it back on. This also meant that we had to run the backfill job, again, to backfill the entries that were created or updated during this window of “write-off”.
Phase 2
Planning: Start reading from the new encrypted table
When we decide that our new encrypted table is sufficiently reliable, we would start reading from it instead of the old plaintext table.
Reality: Start reading from the new encrypted table...after another job
As we prepared to reroute all GET requests away from the old plaintext table, we found out that we still had an active daily cron job that relied on our plaintext table. Now that the data was encrypted, running the job meant we would have to decrypt all entries during each run of the job. That process would be way too expensive.
We ended up uploading the field needed for the job onto a third party site, and triggered the job directly from there. Since the upload job had to be run on all entries, it set us back another week.
Phase 3
Planning: Stop writing to & delete the old plaintext table
After we have been reading from the new encrypted table for a while and detect no more calls to the old plaintext table, we would archive then delete the old table. Then we would be ready to crypto-shred some data!
Reality: Stop writing to & delete the old plaintext table...with one giant merge
This step turned out to be the biggest one-time code change for us because when we planned our rollout, we thought a lot about how we would start using the encrypted table in phases to reduce risk (start write first, then start read too), but we didn’t really think through how we would stop using the plaintext table in the end. So now, even though we were already relying exclusively on the encrypted table, we had to delete a lot of code and refactor a lot of logic all at once.
Takeaways
Looking back, I think there were a couple of things that we could’ve done differently for a smoother rollout.
1. Break phase 3 into 2 phases--stop reading from & stop writing to plaintext table
To avoid having to refactor a lot of code all at once like we did in phase 3, we could have first separated out the historic read and write code from other code as well as from one another . This way, in the last phase, we could remove the read and write code in phases just like how we started using the encrypted table in phases.
This would also have given us an opportunity to discover all the places where we depended on the plaintext table and might have allowed us to detect the daily cron job that set us back in phase 2.
2. Budget more buffer time--your bugs might result in bad data that might take longer to fix than the bugs themselves
Even though we were able to catch some bugs through regression testing in our staging environment, some still made their way to production. But since implementing crypto-shredding involved a complete migration of the data, every time we ran into a bug/obstacle, we, more often than not, ended up having to run a backfill job to resolve the bad data it caused (we all became backfill job experts by the end). Considering that running a job on a large amount of data takes considerable time, we were often set back for multiple days, even when the bug/obstacle itself was quickly discovered and fixed.
Conclusion
Personally, implementing and rolling out crypto-shredding has been an incredible learning experience on how to handle the challenges that often come with implementing complicated designs in a legacy system. It’s natural that any such endeavor comes with setbacks along the way, which is why I’m extra proud of the team for not only achieving our goal of encrypting all of our sensitive data and enabling streamlined deletion, but also doing so with such an elegant solution and rolling it out without any incidents.
If you, too, enjoy overcoming challenges and working on rewarding projects like this...we're hiring!
